Chapter 8 Distributions
8.1 Normal Distribution
Among all the distributions we see in practice, one is overwhelmingly the most common. The symmetric, unimodal, bell curve is ubiquitous throughout statistics. Indeed it is so common, that people often know it as the normal curve or normal distribution50, shown in Figure 8.1. Many variables observed in nature closely follow the normal distribution.
Figure 8.1: A normal curve.
8.1.1 Normal distribution model
The normal distribution model always describes a symmetric, unimodal, bell-shaped curve. However, these curves can look different depending on the details of the model. Specifically, the normal distribution model can be adjusted using two parameters: mean and standard deviation. As you can probably guess, changing the mean shifts the bell curve to the left or right, while changing the standard deviation stretches or constricts the curve. Figure 8.2 shows the normal distribution with mean \(0\) and standard deviation \(1\) in the left panel and the normal distributions with mean \(19\) and standard deviation \(4\) in the right panel. Figure 8.3 shows these distributions on the same axis.
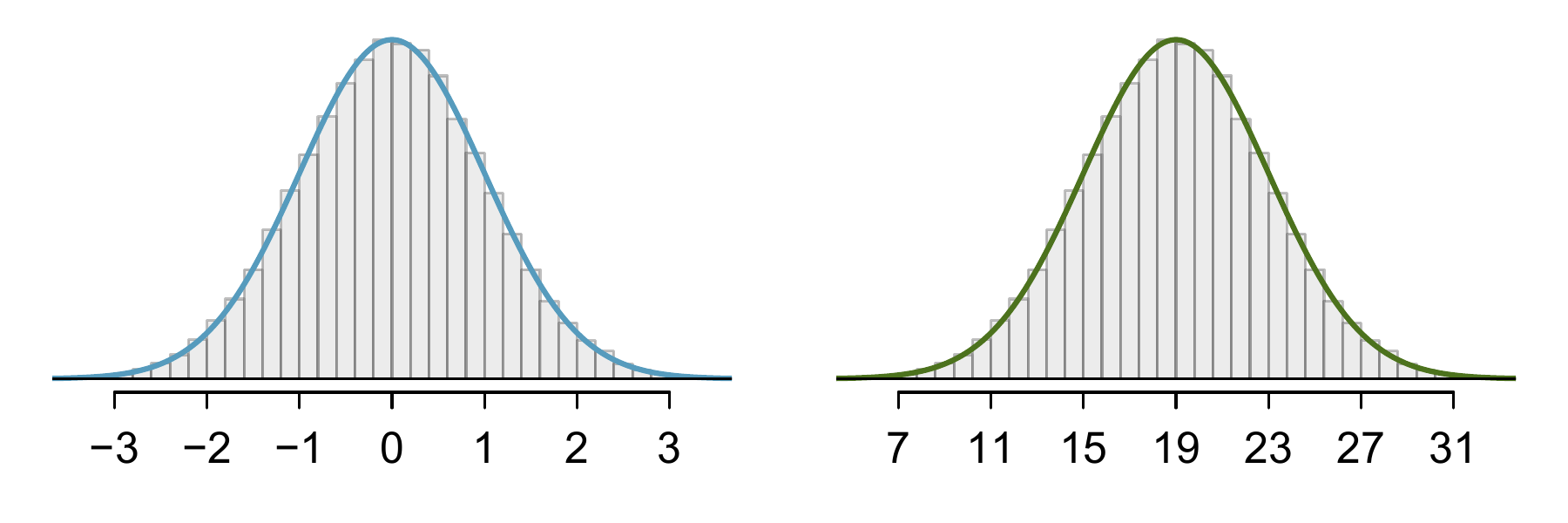
Figure 8.2: Both curves represent the normal distribution, however, they differ in their centre and spread. The normal distribution with mean 0 and standard deviation 1 is called the standard normal distribution.
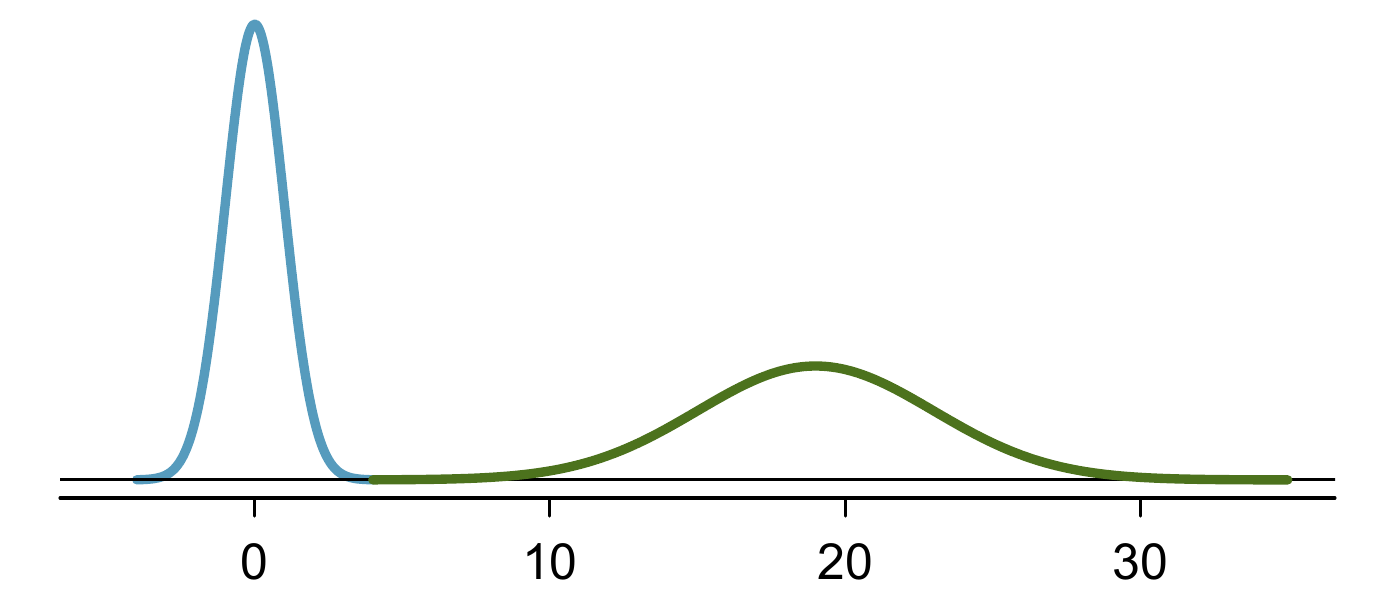
Figure 8.3: The normal models shown in Figure 8.2 but plotted together and on the same scale.“,fig.scap=”Illustration of two normal distributions, on same scale.
If a normal distribution has mean \(\mu\) and standard deviation \(\sigma\), we may write the distribution as \(N(\mu, \sigma)\). The two distributions in Figure 8.3 can be written as \[ \begin{aligned} N(\mu=0,\sigma=1)\quad\text{and}\quad N(\mu=19,\sigma=4) \end{aligned} \] Because the mean and standard deviation describe a normal distribution exactly, they are called the distribution’s parameter.
Guided Practice8.1 Write down the short-hand for a normal distribution with51
- mean5 and standard deviation 3,
- mean-100 and standard deviation 10, and
- mean 2 and standard deviation 9.
8.1.2 Standardizing with \(Z\)-scores
We use the standard deviation as a guide. Ann is 1 standard deviation above average on the SAT: \(1500 + 300=1800\). Tom is 0.6 standard deviations above the mean on the ACT: \(21+0.6\times 5=24\). In Figure 8.4, we can see that Ann tends to do better with respect to everyone else than Tom did, so her score was better.
| Summary metric | SAT | ACT |
|---|---|---|
| Mean | 1500 | 21 |
| SD | 300 | 5 |
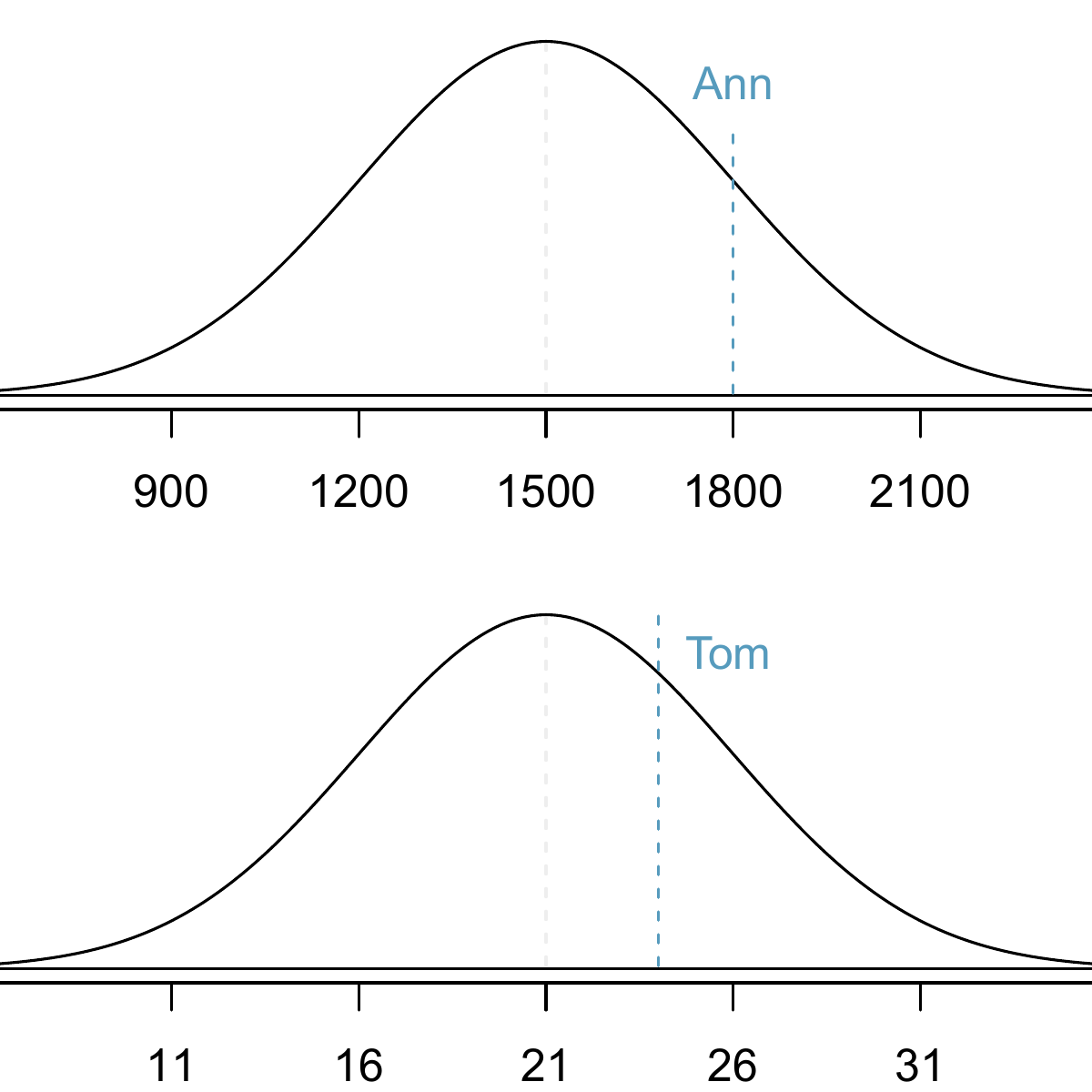
Figure 8.4: Ann’s and Tom’s scores shown with the distributions of SAT and ACT scores.
Example 8.1 used a standardization technique called a \(Z\)-score, a method most commonly employed for nearly normal observations but that may be used with any distribution. The \(Z\)-score of an observation is defined as the number of standard deviations it falls above or below the mean. If the observation is one standard deviation above the mean, its \(Z\)-score is 1. If it is 1.5 standard deviations the mean, then its \(Z\)-score is -1.5. If \(x\) is an observation from a distribution \(N(\mu, \sigma)\), we define the \(Z\)-score mathematically as
\[ Z = \frac{x-\mu}{\sigma} \] Using \(\mu_{SAT}=1500\), \(\sigma_{SAT}=300\), and \(x_{Ann}=1800\), we find Ann’s \(Z\)-score: \[ Z_{Ann} = \frac{x_{Ann} - \mu_{SAT}}{\sigma_{SAT}} = \frac{1800-1500}{300} = 1 \]
Observations above the mean always have positive \(Z\)-scores while those below the mean have negative \(Z\)-scores. If an observation is equal to the mean (e.g. SAT score of 1500), then the \(Z\)-score is \(0\).
Guided Practice8.3 Let \(X\) represent a random variable from \(N(\mu=3, \sigma=2)\), and suppose we observe \(x=5.19\).
- Find the \(Z\)-score of \(x\).
- Use the \(Z\)-score to determine how many standard deviations above or below the mean \(x\) falls.53
We can use \(Z\)-scores to roughly identify which observations are more unusual than others. One observation \(x_1\) is said to be more unusual than another observation \(x_2\) if the absolute value of its \(Z\)-score is larger than the absolute value of the other observation’s \(Z\)-score: \(|Z_1| > |Z_2|\). This technique is especially insightful when a distribution is symmetric.
We can use the normal model to find percentiles. A normal probability table, which lists \(Z\)-scores and corresponding percentiles used to be used to identify a percentile based on the \(Z\)-score (and vice versa). Looking up statistical tables is no longer needed as finding these values in R and other software is very simple.
# calculate the probability P(Z<0.43) - i.e. what is the probability of standard
# normal variable taking a value less than 0.43?
pnorm(q = 0.43, mean = 0, sd = 1)
#> [1] 0.666
# calculate the $Z$-score satisfying P(Z<z)=0.80 - i.e. what value is at the 80th
# percentile of a standard normal distribution?
qnorm(p = 0.8, mean = 0, sd = 1)
#> [1] 0.842
# to see more options, type '?rnorm'8.1.3 Normal probability examples
Cumulative SAT scores are approximated well by a normal model, \(N(\mu=1500, \sigma=300)\).
First, always draw and label a picture of the normal distribution. (Drawings need not be exact to be useful.) We are interested in the chance she scores above 1630, so we shade this upper tail:
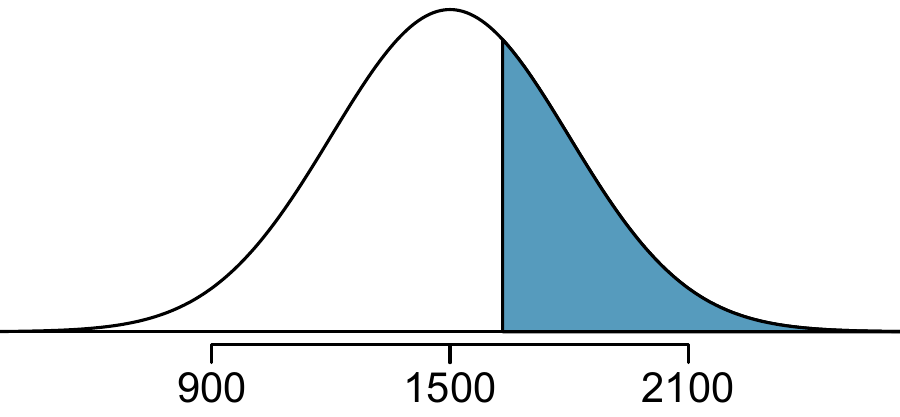
The picture shows the mean and the values at 2 standard deviations above and below the mean. The simplest way to find the shaded area under the curve makes use of the \(Z\)-score of the cutoff value. With \(\mu=1500\), \(\sigma=300\), and the cutoff value \(x=1630\), the \(Z\)-score is computed as
\[
Z = \frac{x - \mu}{\sigma} = \frac{1630 - 1500}{300} = \frac{130}{300} = 0.43
\]
We look up the percentile of \(Z=0.43\) in the normal probability table or using statistical software, which yields 0.6664. However, the percentile describes those who had a \(Z\)-score than 0.43. To find the area \(Z=0.43\), we compute one minus the area of the lower tail:
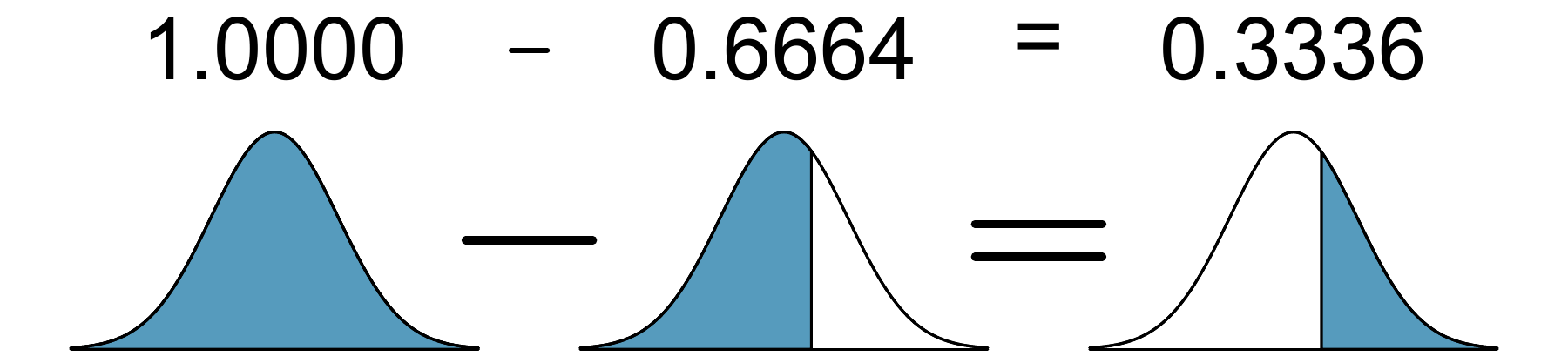 The probability Shannon scores at least 1630 on the SAT is 0.3336.
The probability Shannon scores at least 1630 on the SAT is 0.3336.
After drawing a figure to represent the situation, identify the \(Z\)-score for the observation of interest.
Example 8.3 Edward earned a 1400 on his SAT. What is his percentile?
First, a picture is needed. Edward’s percentile is the proportion of people who do not get as high as a 1400. These are the scores to the left of 1400.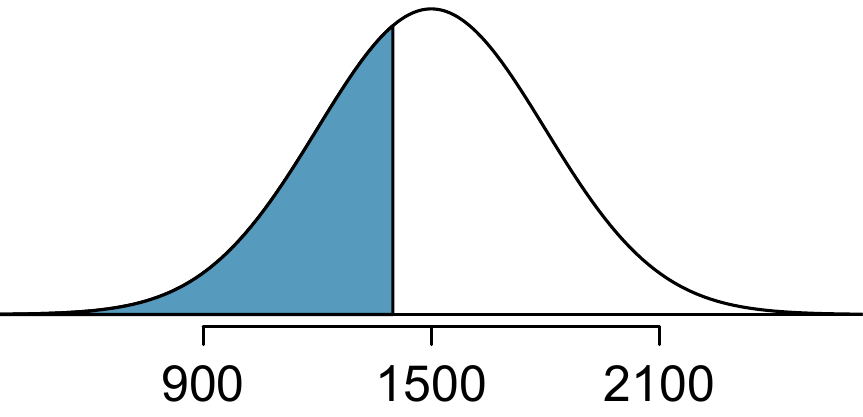 Identifying the mean \(\mu=1500\), the standard deviation \(\sigma=300\), and the cutoff for the tail area \(x=1400\) makes it easy to compute the \(Z\)-score:
\[
Z = \frac{x - \mu}{\sigma} = \frac{1400 - 1500}{300} = -0.33
\]
Using the normal probability table, identify the row of \(-0.3\) and column of \(0.03\), which corresponds to the probability \(0.3707\). Edward is at the \(37^{th}\) percentile.
Identifying the mean \(\mu=1500\), the standard deviation \(\sigma=300\), and the cutoff for the tail area \(x=1400\) makes it easy to compute the \(Z\)-score:
\[
Z = \frac{x - \mu}{\sigma} = \frac{1400 - 1500}{300} = -0.33
\]
Using the normal probability table, identify the row of \(-0.3\) and column of \(0.03\), which corresponds to the probability \(0.3707\). Edward is at the \(37^{th}\) percentile.
Guided Practice8.9 Stuart earned an SAT score of 2100. Draw a picture for each part.
- What is his percentile?
- What percent of SAT takers did better than Stuart?59
Based on a sample of 100 men,60 the heights of male adults between the ages 20 and 62 in the US is nearly normal with mean 70.0’’ and standard deviation 3.3’’.
Guided Practice8.10 Mike is 5’7’’ and Jim is 6’4’’.
- What is Mike’s height percentile?
- What is Jim’s height percentile?
The last several problems have focused on finding the probability or percentile for a particular observation. What if you would like to know the observation corresponding to a particular percentile?
Example 8.4 Erik’s height is at the \(40^{th}\) percentile. How tall is he?
As always, first draw the picture.
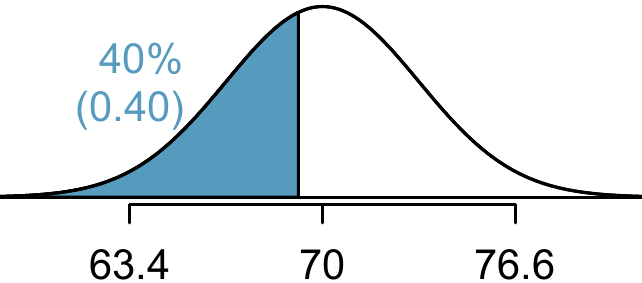
In this case, the lower tail probability is known (0.40), which can be shaded on the diagram. We want to find the observation that corresponds to this value. As a first step in this direction, we determine the \(Z\)-score associated with the \(40^{th}\) percentile.
Because the percentile is below 50%, we know \(Z\) will be negative. Looking in the negative part of the normal probability table, we search for the probability inside the table closest to 0.4000. We find that 0.4000 falls in row \(-0.2\) and between columns \(0.05\) and \(0.06\). Since it falls closer to \(0.05\), we take this one: \(Z=-0.25\).
Knowing \(Z_{Erik}=-0.25\) and the population parameters \(\mu=70\) and \(\sigma=3.3\) inches, the \(Z\)-score formula can be set up to determine Erik’s unknown height, labelled \(x_{Erik}\): \[ -0.25 = Z_{Erik} = \frac{x_{Erik} - \mu}{\sigma} = \frac{x_{Erik} - 70}{3.3} \] Solving for \(x_{Erik}\) yields the height 69.18 inches. That is, Erik is about 5’9’’ (this is notation for 5-feet, 9-inches).Example 8.5 What is the adult male height at the \(82^{nd}\) percentile?
Again, we draw the figure first.
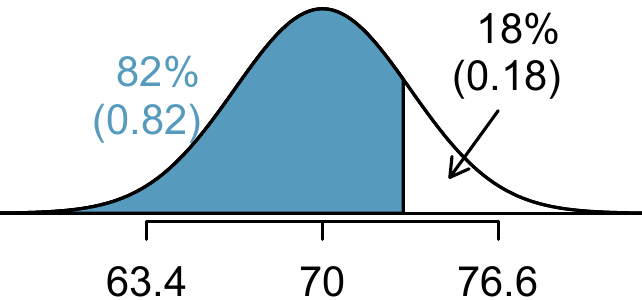
Guided Practice8.11
(a) What is the \(95^{th}\) percentile for SAT scores?
(b) What is the \(97.5^{th}\) percentile of the male heights? As always with normal probability problems, first draw a picture.62
Guided Practice8.12
(a) What is the probability that a randomly selected male adult is at least 6’2’’ (74 inches)?
(b) What is the probability that a male adult is shorter than 5’9’’ (69 inches)?63
Example 8.6 What is the probability that a random adult male is between 5’9’’ and 6’2’’?
These heights correspond to 69 inches and 74 inches. First, draw the figure. The area of interest is no longer an upper or lower tail.
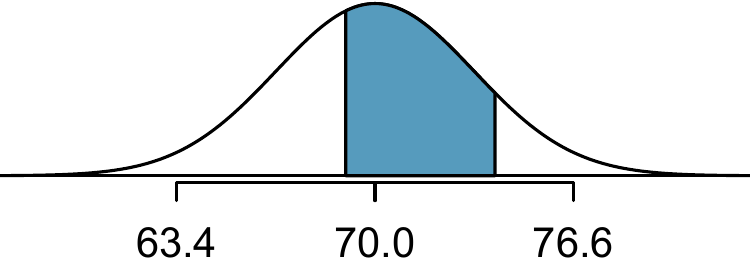
The total area under the curve is 1. If we find the area of the two tails that are not shaded (from Guided Practice 8.12, these areas are \(0.3821\) and \(0.1131\)), then we can find the middle area:

8.1.4 68-95-99.7 rule
Here, we present a useful rule of thumb for the probability of falling within 1, 2, and 3 standard deviations of the mean in the normal distribution. This will be useful in a wide range of practical settings, especially when trying to make a quick estimate without a calculator or Z-table.
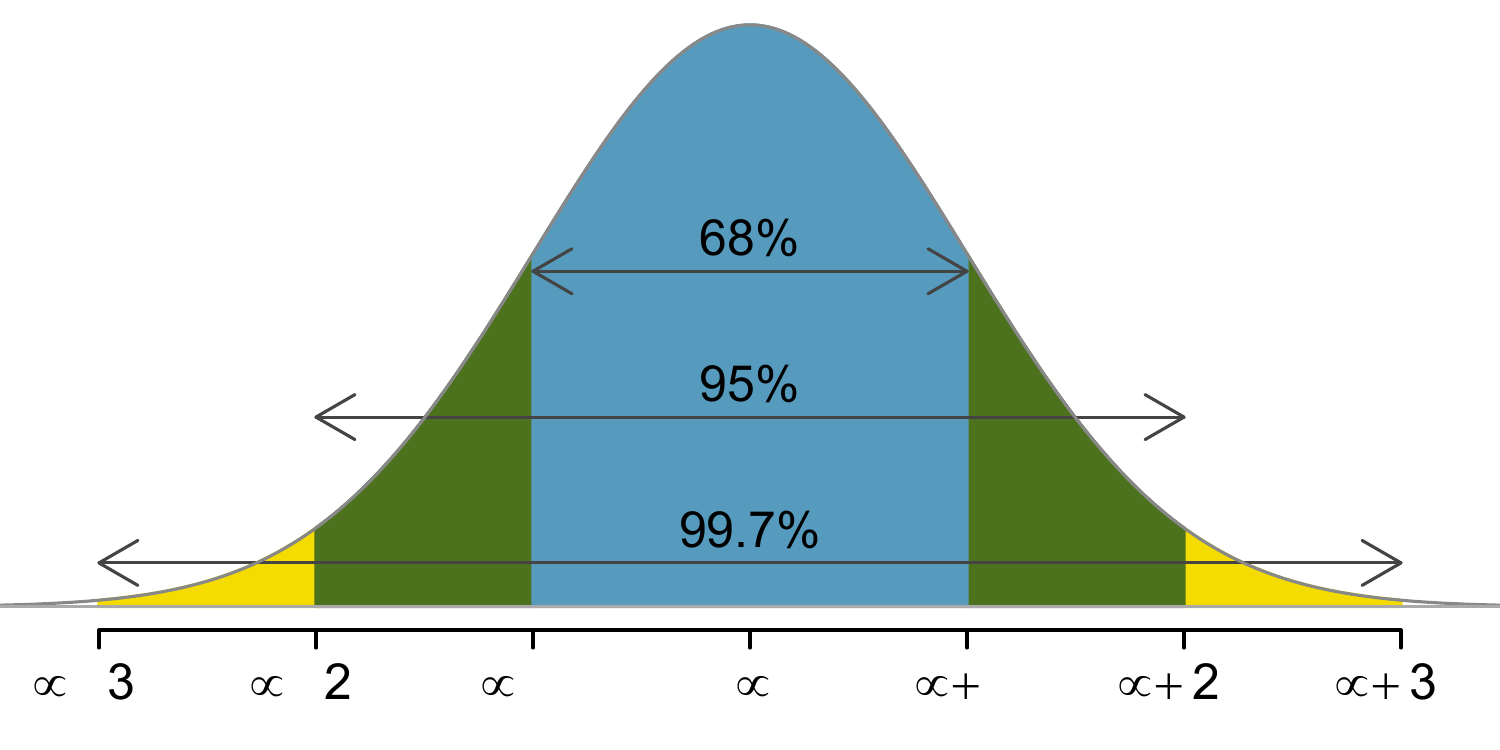
Figure 8.5: Probabilities for falling within 1, 2 and 3 standard deviations of the mean in a normal distribution.
It is possible for a normal random variable to fall 4,~5, or~even more standard deviations from the mean. However, these occurrences are very rare if the data are nearly normal. The probability of being further than 4 standard deviations from the mean is about 1-in-15,000. For 5 and 6 standard deviations, it is about 1-in-2 million and 1-in-500 million, respectively.
Guided Practice8.16 SAT scores closely follow the normal model with mean \(\mu = 1500\) and standard deviation \(\sigma = 300\).
- About what percent of test takers score 900 to 2100?
- What percent score between 1500 and 2100?67
8.2 Evaluating the Normal Approximation
Many processes can be well approximated by the normal distribution. We have already seen two good examples: SAT scores and the heights of US adult males. While using a normal model can be extremely convenient and helpful, it is important to remember normality is always an approximation. Testing the appropriateness of the normal assumption is a key step in many data analyses.
Example 8.4 suggests the distribution of heights of US males is well approximated by the normal model. We are interested in proceeding under the assumption that the data are normally distributed, but first we must check to see if this is reasonable.
There are two visual methods for checking the assumption of normality, which can be implemented and interpreted quickly. The first is a simple histogram with the best fitting normal curve overlaid on the plot, as shown in the left panel of Figure 8.6. The sample mean \(\bar{x}\) and standard deviation \(s\) are used as the parameters of the best fitting normal curve. The closer this curve fits the histogram, the more reasonable the normal model assumption. Another more common method is examining a normal probability plot,68 shown in the right panel of Figure 8.6. The closer the points are to a perfect straight line, the more confident we can be that the data follow the normal model.
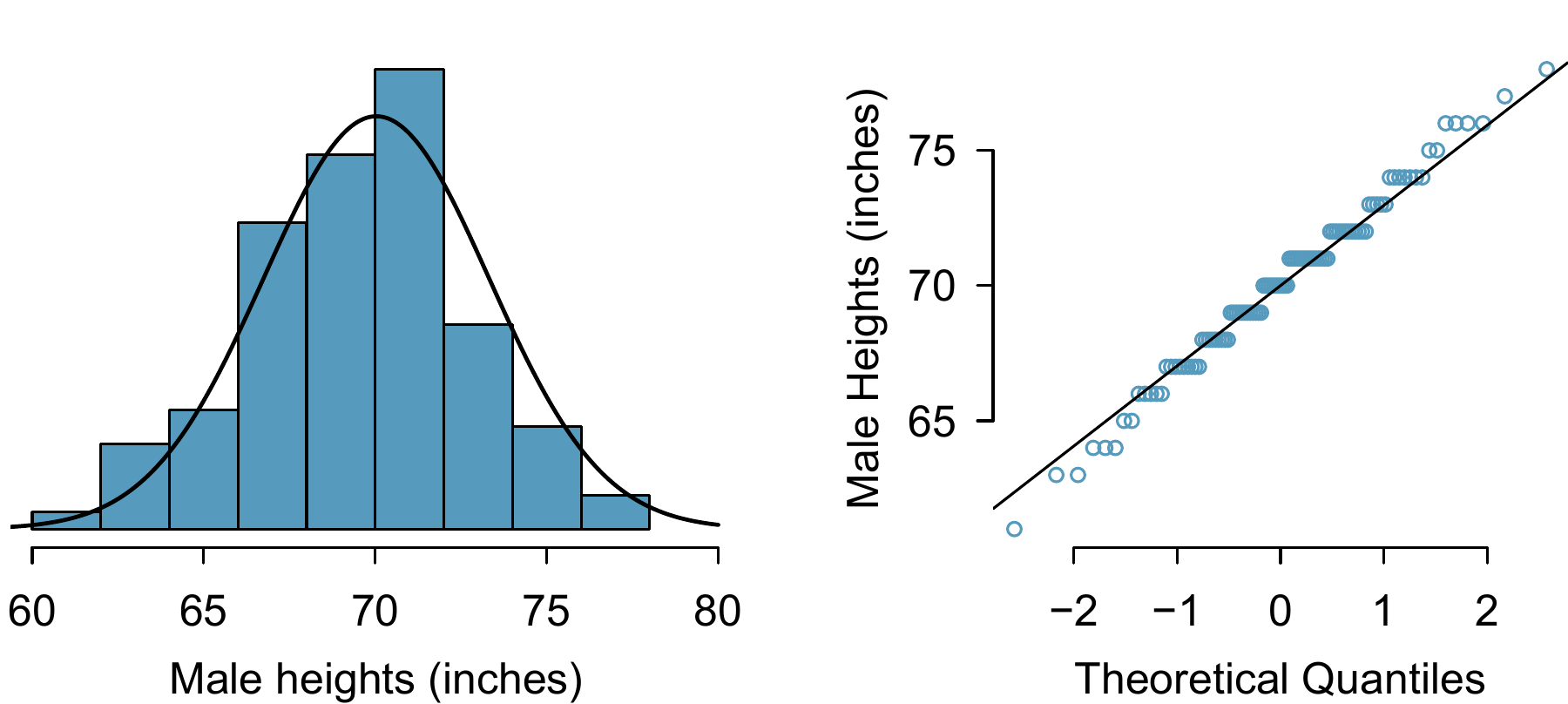
Figure 8.6: A sample of 100 male heights. The observations are rounded to the nearest whole inch, explaining why the points appear to jump in increments in the normal probability plot.
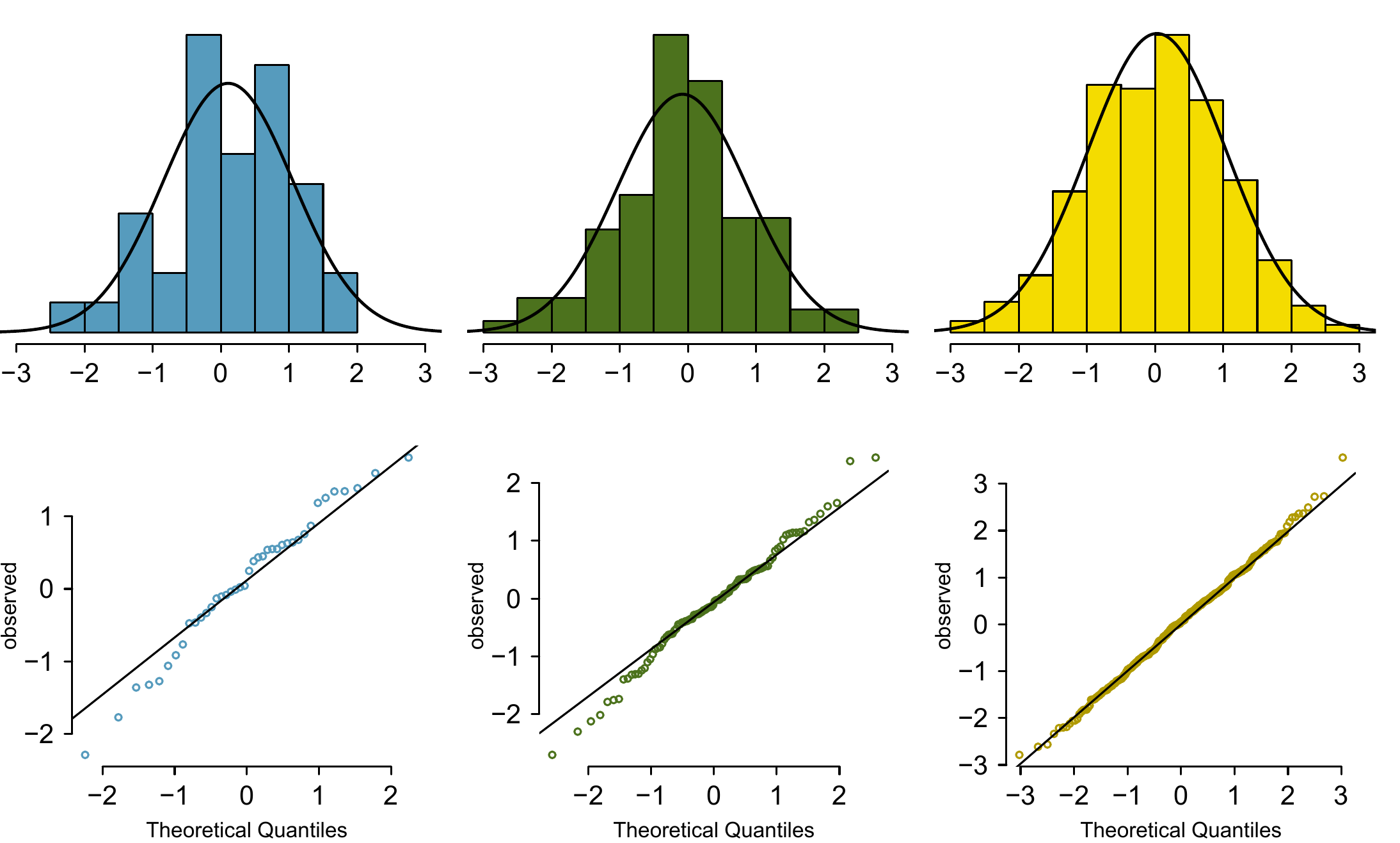
Figure 8.7: Histograms and normal probability plots for three simulated normal data sets; \(n=40\) (left), \(n=100\) (middle), \(n=400\) (right).
The left panels show the histogram (top) and normal probability plot (bottom) for the simulated data set with 40 observations. The data set is too small to really see clear structure in the histogram. The normal probability plot also reflects this, where there are some deviations from the line. We should expect deviations of this amount for such a small data set.
The middle panels show diagnostic plots for the data set with 100 simulated observations. The histogram shows more normality and the normal probability plot shows a better fit. While there are a few observations that deviate noticeably from the line, they are not particularly extreme.
The data set with 400 observations has a histogram that greatly resembles the normal distribution, while the normal probability plot is nearly a perfect straight line. Again in the normal probability plot there is one observation (the largest) that deviates slightly from the line. If that observation had deviated 3 times further from the line, it would be of greater importance in a real data set. Apparent outliers can occur in normally distributed data but they are rare.
Notice the histograms look more normal as the sample size increases, and the normal probability plot becomes straighter and more stable.
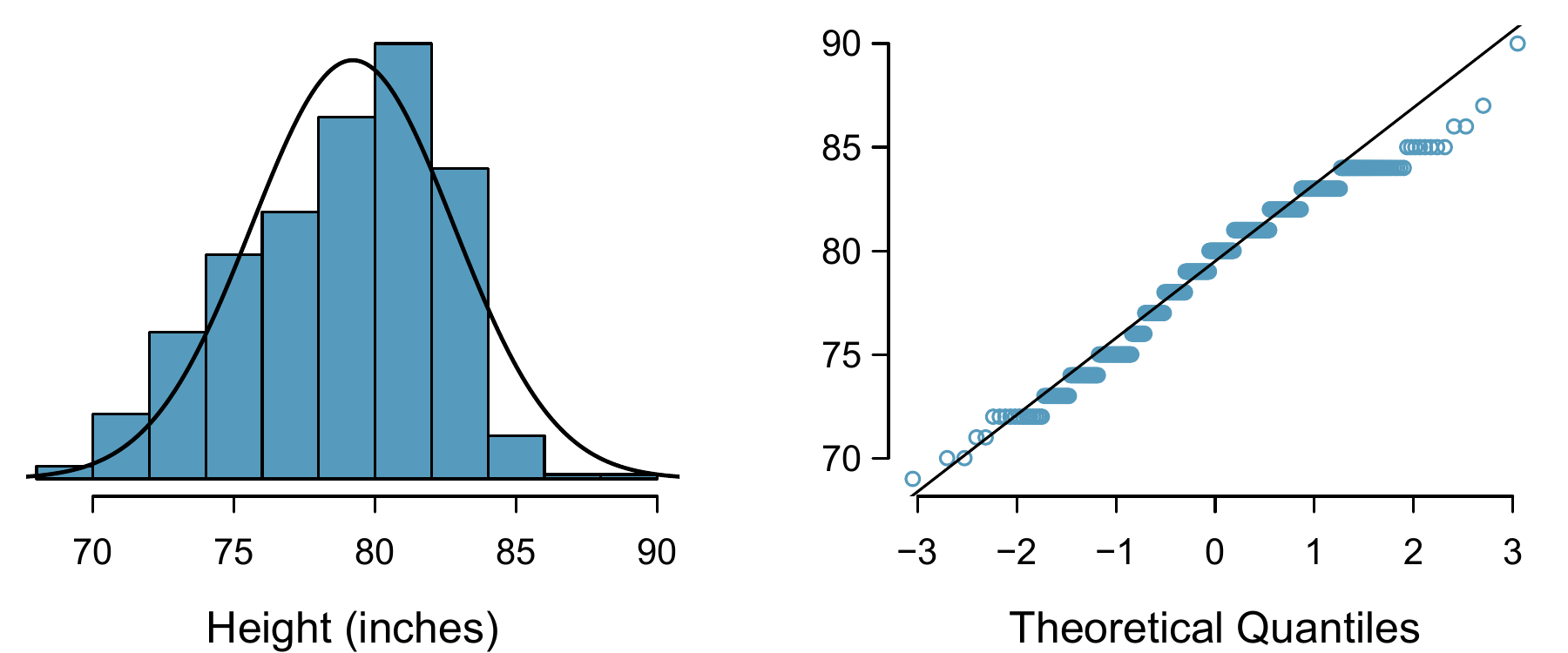
Figure 8.8: Histogram and normal probability plot for the NBA heights from the 2008-9 season.
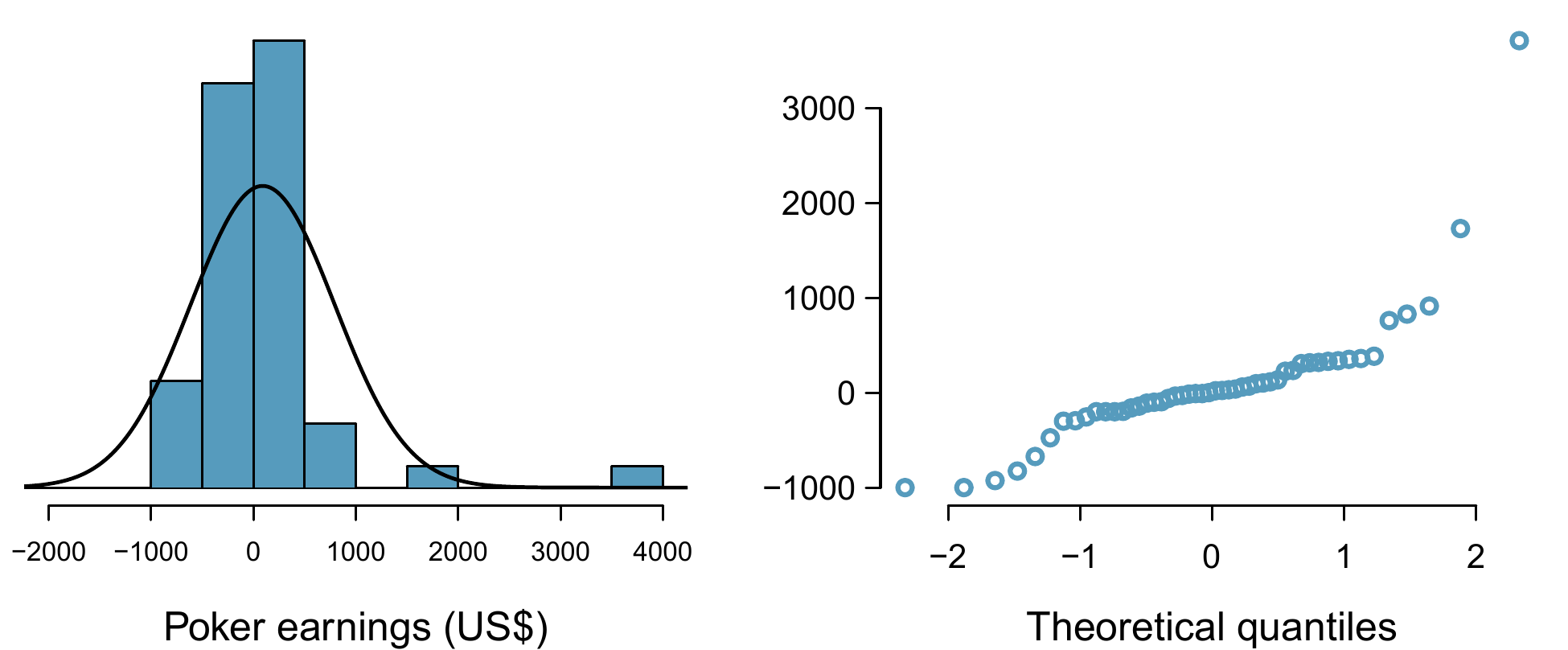
Figure 8.9: A histogram of poker data with normal plot fit and normal probability plot.
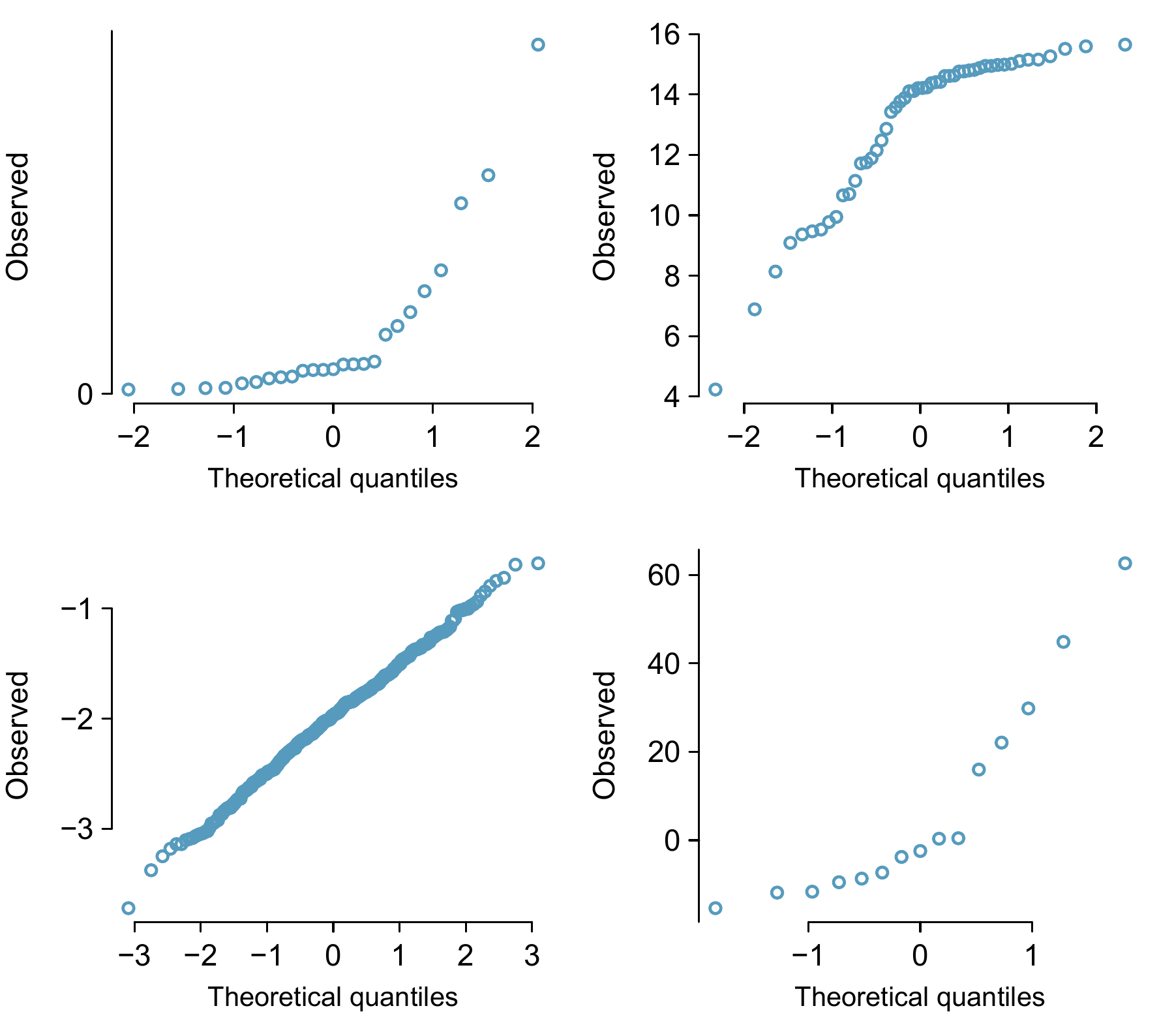
Figure 8.10: Four normal probability plots for Guided Practice 8.17.
When observations spike downwards on the left side of a normal probability plot, it means the data have more outliers in the left tail than we’d expect under a normal distribution. When observations spike upwards on the right side, it means the data have more outliers in the right tail than what we’d expect under the normal distribution.
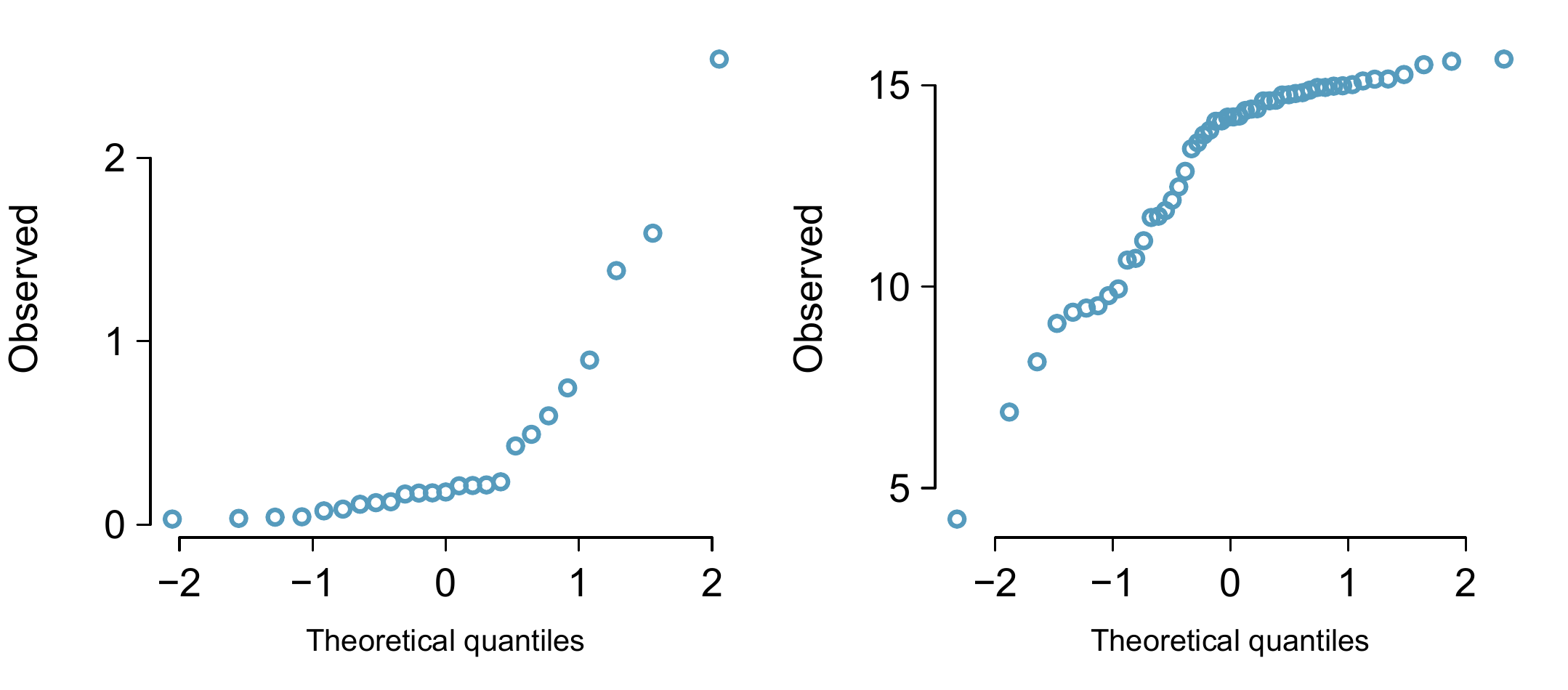
Figure 8.11: Normal probability plots for Guided Practice 8.18.
8.3 Geometric Distribution
How long should we expect to flip a coin until it turns up \(heads\)? Or how many times should we expect to roll a die until we get a \(1\)? These questions can be answered using the geometric distribution. We first formalize each trial – such as a single coin flip or die toss – using the Bernoulli distribution, and then we combine these with our tools from probability (Chapter 7) to construct the geometric distribution.
8.3.1 Bernoulli distribution
Stanley Milgram began a series of experiments in 1963 to estimate what proportion of people would willingly obey an authority and give severe shocks to a stranger. Milgram found that about 65% of people would obey the authority and give such shocks. Over the years, additional research suggested this number is approximately consistent across communities and time.72
Each person in Milgram’s experiment can be thought of as a trial. We label a person a success if she refuses to administer the worst shock. A person is labelled a failure if she administers the worst shock. Because only 35% of individuals refused to administer the most severe shock, we denote the probability of a success with \(p=0.35\). The probability of a failure is sometimes denoted with \(q=1-p\).
Thus, success or failure is recorded for each person in the study. When an individual trial only has two possible outcomes, it is called a Bernoulli random variable.
Bernoulli random variables are often denoted as \(1\) for a success and \(0\) for a failure. In addition to being convenient in entering data, it is also mathematically handy. Suppose we observe ten trials: \[ 0\ 1\ 1\ 1\ 1\ 0\ 1\ 1\ 0\ 0 \] Then the sample proportion, \(\hat{p}\), is the sample mean of these observations: \[ \hat{p} = \frac{\#\text{ of successes}}{\#\text{ of trials}} = \frac{0+1+1+1+1+0+1+1+0+0}{10} = 0.6 \] This mathematical inquiry of Bernoulli random variables can be extended even further. Because \(0\) and \(1\) are numerical outcomes, we can define the mean and standard deviation of a Bernoulli random variable.73
In general, it is useful to think about a Bernoulli random variable as a random process with only two outcomes: a success or failure. Then we build our mathematical framework using the numerical labels \(1\) and \(0\) for successes and failures, respectively.
8.3.2 Geometric distribution
Example 8.10 Dr. Smith wants to repeat Milgram’s experiments but she only wants to sample people until she finds someone who will not inflict the worst shock.74 If the probability a person will not give the most severe shock is still 0.35 and the subjects are independent, what are the chances that she will stop the study after the first person? The second person? The third? What about if it takes her \(n-1\) individuals who will administer the worst shock before finding her first success, i.e. the first success is on the \(n^{th}\) person? (If the first success is the fifth person, then we say \(n=5\).)
The probability of stopping after the first person is just the chance the first person will not administer the worst shock: \(1-0.65=0.35\). The probability it will be the second person is \[ \begin{aligned} &P(\text{second person is the first to not administer the worst shock}) \\ &\quad = P(\text{the first will, the second won't}) = (0.65)(0.35) = 0.228 \end{aligned} \]
Likewise, the probability it will be the third person is \((0.65)(0.65)(0.35) = 0.148\).
If the first success is on the \(n^{th}\) person, then there are \(n-1\) failures and finally 1 success, which corresponds to the probability \((0.65)^{n-1}(0.35)\). This is the same as \((1-0.35)^{n-1}(0.35)\).Example 8.10 illustrates what is called the geometric distribution, which describes the waiting time until a success for independent and identically distributed (iid) Bernoulli random variables. In this case, the independence aspect just means the individuals in the example don’t affect each other, and identical means they each have the same probability of success.
The geometric distribution from Example 8.10 is shown in Figure 8.12. In general, the probabilities for a geometric distribution decrease exponentially fast.
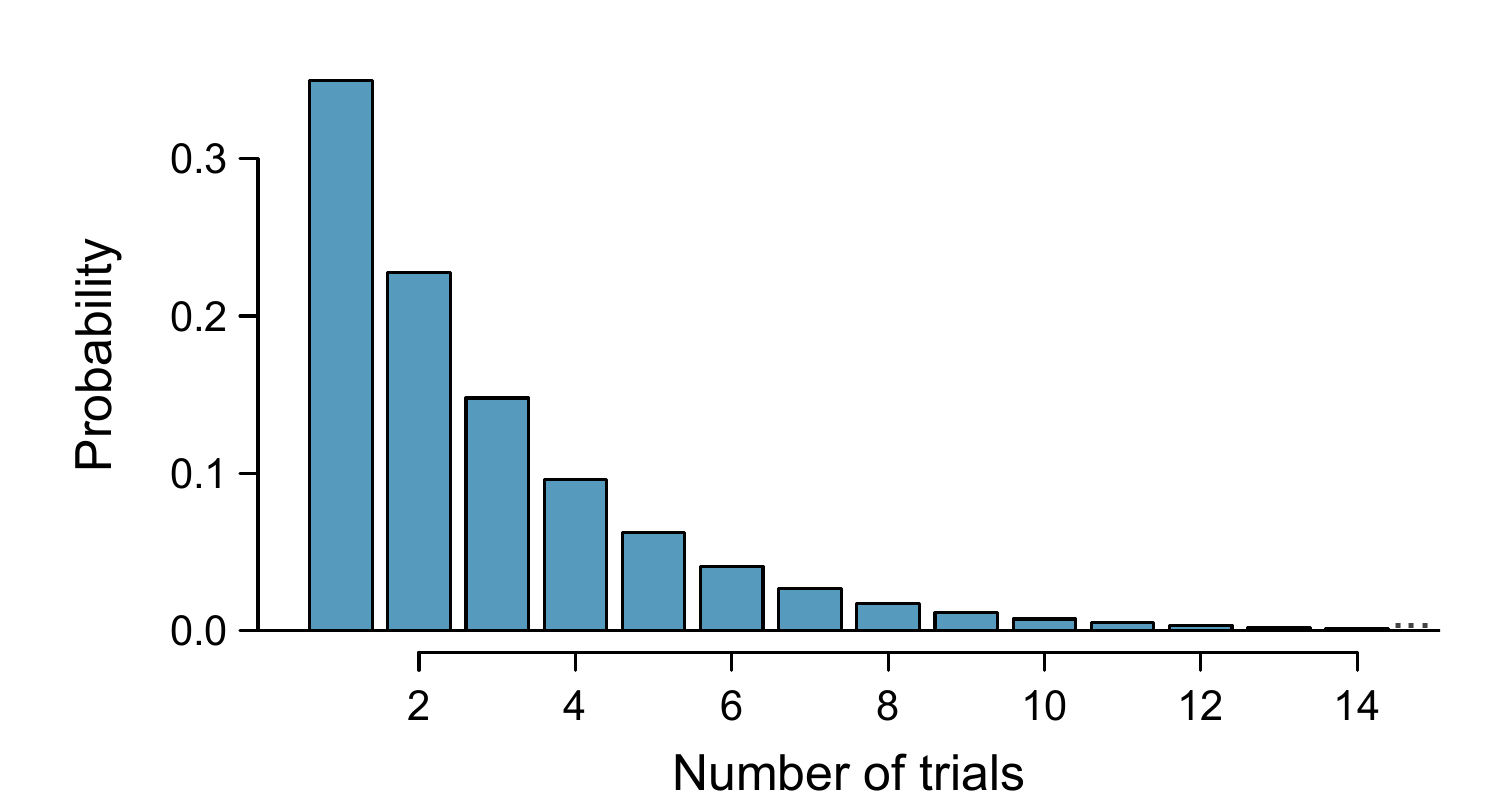
Figure 8.12: The geometric distribution when the probability of success is \(p=0.35\).
While this text will not derive the formulas for the mean (expected) number of trials needed to find the first success or the standard deviation or variance of this distribution, we present general formulas for each.
It is no accident that we use the symbol \(\mu\) for both the mean and expected value. The mean and the expected value are one and the same.
The left side of Equation (8.1) says that, on average, it takes \(1/p\) trials to get a success. This mathematical result is consistent with what we would expect intuitively. If the probability of a success is high (e.g. 0.8), then we don’t usually wait very long for a success: \(1/0.8 = 1.25\) trials on average. If the probability of a success is low (e.g. 0.1), then we would expect to view many trials before we see a success: \(1/0.1 = 10\) trials.
Example 8.11 What is the chance that Dr. Smith will find the first success within the first 4 people?
This is the chance it is the first (\(n=1\)), second (\(n=2\)), third (\(n=3\)), or fourth (\(n=4\)) person as the first success, which are four disjoint outcomes. Because the individuals in the sample are randomly sampled from a large population, they are independent. We compute the probability of each case and add the separate results: \[ \begin{aligned} &P(n=1, 2, 3,\text{ or }4) \\ & \quad = P(n=1)+P(n=2)+P(n=3)+P(n=4) \\ & \quad = (0.65)^{1-1}(0.35) + (0.65)^{2-1}(0.35) + (0.65)^{3-1}(0.35) + (0.65)^{4-1}(0.35) \\ & \quad = 0.82 \end{aligned} \] There is an 82% chance that she will end the study within 4 people.Example 8.12 Suppose in one region it was found that the proportion of people who would administer the worst shock was “only” 55%. If people were randomly selected from this region, what is the expected number of people who must be checked before one was found that would be deemed a success? What is the standard deviation of this waiting time?
A success is when someone will inflict the worst shock, which has probability \(p=1-0.55=0.45\) for this region. The expected number of people to be checked is \(1/p = 1/0.45 = 2.22\) and the standard deviation is \(\sqrt{(1-p)/p^2} = 1.65\).The independence assumption is crucial to the geometric distribution’s accurate description of a scenario. Mathematically, we can see that to construct the probability of the success on the \(n^{th}\) trial, we had to use the Multiplication Rule for Independent Processes. It is no simple task to generalize the geometric model for dependent trials.
8.4 Binomial Distribution
Example 8.13 Suppose we randomly selected four individuals to participate in the “shock” study. What is the chance exactly one of them will be a success? Let’s call the four people Allen (\(A\)), Brittany (\(B\)), Caroline (\(C\)), and Damian (\(D\)) for convenience. Also, suppose 35% of people are successes as in the previous version of this example.
Let’s consider a scenario where one person refuses: \[ \begin{aligned} &P(A=\texttt{refuse},\text{ }B=\texttt{shock},\text{ }C=\texttt{shock},\text{ }D=\texttt{shock}) \\ &\quad = P(A=\texttt{refuse})\ P(B=\texttt{shock})\ P(C=\texttt{shock})\ P(D=\texttt{shock}) \\ &\quad = (0.35) (0.65) (0.65) (0.65) = (0.35)^1 (0.65)^3 = 0.096 \end{aligned} \] But there are three other scenarios: Brittany, Caroline, or Damian could have been the one to refuse. In each of these cases, the probability is again \((0.35)^1(0.65)^3\). These four scenarios exhaust all the possible ways that exactly one of these four people could refuse to administer the most severe shock, so the total probability is \(4\times(0.35)^1(0.65)^3 = 0.38\).8.4.1 The binomial distribution
The scenario outlined in Example 8.13 is a special case of what is called the binomial distribution. The binomial distribution describes the probability of having exactly \(k\) successes in \(n\) independent Bernoulli trials with probability of a success \(p\) (in Example 8.13, \(n=4\), \(k=1\), \(p=0.35\)). We would like to determine the probabilities associated with the binomial distribution more generally, i.e. we want a formula where we can use \(n\), \(k\), and \(p\) to obtain the probability. To do this, we reexamine each part of the example.
There were four individuals who could have been the one to refuse, and each of these four scenarios had the same probability. Thus, we could identify the final probability as \[ [\#\text{ of scenarios}] \times P(\text{single scenario}) \tag{8.2} \] The first component of this equation is the number of ways to arrange the \(k=1\) successes among the \(n=4\) trials. The second component is the probability of any of the four (equally probable) scenarios.
Consider \(P(\)single scenario\()\) under the general case of \(k\) successes and \(n-k\) failures in the \(n\) trials. In any such scenario, we apply the Multiplication Rule for independent events: \[ p^k(1-p)^{n-k} \] This is our general formula for \(P(\)single scenario\()\).
Secondly, we introduce a general formula for the number of ways to choose \(k\) successes in \(n\) trials, i.e. arrange \(k\) successes and \(n-k\) failures: \[ {n\choose k} = \frac{n!}{k!(n-k)!} \] The quantity \({n\choose k}\) is read n choose k.79 The exclamation mark notation (e.g. \(k!\)) denotes a factorial expression. \[ \begin{aligned} & 0! = 1 \\ & 1! = 1 \\ & 2! = 2\times1 = 2 \\ & 3! = 3\times2\times1 = 6 \\ & 4! = 4\times3\times2\times1 = 24 \\ & \vdots \\ & n! = n\times(n-1)\times...\times3\times2\times1 \end{aligned} \tag{8.3} \] Using the formula, we can compute the number of ways to choose \(k=1\) successes in \(n=4\) trials: \[ {4 \choose 1} = \frac{4!}{1!(4-1)!} = \frac{4!}{1!3!} = \frac{4\times3\times2\times1}{(1)(3\times2\times1)} = 4 \] This result is exactly what we found by carefully thinking of each possible scenario in Example 8.13.
Substituting \(n\) choose \(k\) for the number of scenarios and \(p^k(1-p)^{n-k}\) for the single scenario probability in Equation (8.2) yields the general binomial formula.
Remark (Is it binomial? Four conditions to check.).
- The trials are independent.
- The number of trials, \(n\), is fixed.
- Each trial outcome can be classified as a success or failure.
- The probability of a success, \(p\), is the same for each trial.
Example 8.14 What is the probability that 3 of 8 randomly selected students will refuse to administer the worst shock, i.e. 5 of 8 will?
We would like to apply the binomial model, so we check our conditions. The number of trials is fixed (\(n=8\)) (condition 2) and each trial outcome can be classified as a success or failure (condition 3). Because the sample is random, the trials are independent (condition 1) and the probability of a success is the same for each trial (condition 4).
In the outcome of interest, there are \(k=3\) successes in \(n=8\) trials, and the probability of a success is \(p=0.35\). So the probability that 3 of 8 will refuse is given by \[ \begin{aligned} { 8 \choose 3}(0.35)^3(1-0.35)^{8-3} =& \frac{8!}{3!(8-3)!}(0.35)^3(1-0.35)^{8-3} \\ =& \frac{8!}{3!5!}(0.35)^3(0.65)^5 \end{aligned} \]
Dealing with the factorial part: \[ \frac{8!}{3!5!} = \frac{8\times7\times6\times5\times4\times3\times2\times1}{(3\times2\times1)(5\times4\times3\times2\times1)} = \frac{8\times7\times6}{3\times2\times1} = 56 \] Using \((0.35)^3(0.65)^5 \approx 0.005\), the final probability is about \(56\times 0.005 = 0.28\).Guided Practice8.25 Suppose these four friends do not know each other and we can treat them as if they were a random sample from the population. Is the binomial model appropriate? What is the probability that
- none of them will develop a severe lung condition?
- One will develop a severe lung condition?
- That no more than one will develop a severe lung condition?82
Guided Practice8.27 Suppose you have 7 friends who are smokers and they can be treated as a random sample of smokers.
- How many would you expect to develop a severe lung condition, i.e. what is the mean?
- What is the probability that at most 2 of your 7 friends will develop a severe lung condition.84
Next we consider the first term in the binomial probability, \(n\) choose \(k\) under some special scenarios.
Guided Practice8.29
- How many ways can you arrange one success and \(n-1\) failures in \(n\) trials?
- How many ways can you arrange \(n-1\) successes and one failure in \(n\) trials?86
8.4.2 Normal approximation to the binomial distribution
The binomial formula is cumbersome when the sample size (\(n\)) is large, particularly when we consider a range of observations. In some cases we may use the normal distribution as an easier and faster way to estimate binomial probabilities.
Example 8.15 Approximately 14.5% of the Australian adult population smokes cigarettes.87 A local government believed their community had a lower smoker rate and commissioned a survey of 400 randomly selected individuals. The survey found that only 39 of the 400 participants smoke cigarettes. If the true proportion of smokers in the community was really 14.5%, what is the probability of observing 39 or fewer smokers in a sample of 400 people? We leave the usual verification that the four conditions for the binomial model are valid as an exercise.
The question posed is equivalent to asking, what is the probability of observing \(k=0\), 1, …, 38, or 39 smokers in a sample of \(n=400\) when \(p=0.145\)? We can compute these 40 different probabilities and add them together to find the answer: \[ \begin{aligned} &P(k=0\text{ or }k=1\text{ or }\cdots\text{ or } k=39) \\ &\qquad= P(k=0) + P(k=1) + \cdots + P(k=39) \\ &\qquad=0.0030 \end{aligned} \] If the true proportion of smokers in the community is \(p=0.145\), then the probability of observing 39 or fewer smokers in a sample of \(n=400\) is 0.0030. In R this can be calculated as follows:# calculate the probability P(X<=39) when X has Bin(n=400, p=0.145) distribution
pbinom(q = 39, size = 400, prob = 0.145, lower.tail = TRUE)
#> [1] 0.00303Although the once tedious computation in Example 8.15 is now easily performed using the software, there are still occasions when calculating the exact binomial probabilities is best avoided. We might wonder, is it reasonable to use the normal model in place of the binomial distribution? Surprisingly, yes, if certain conditions are met.
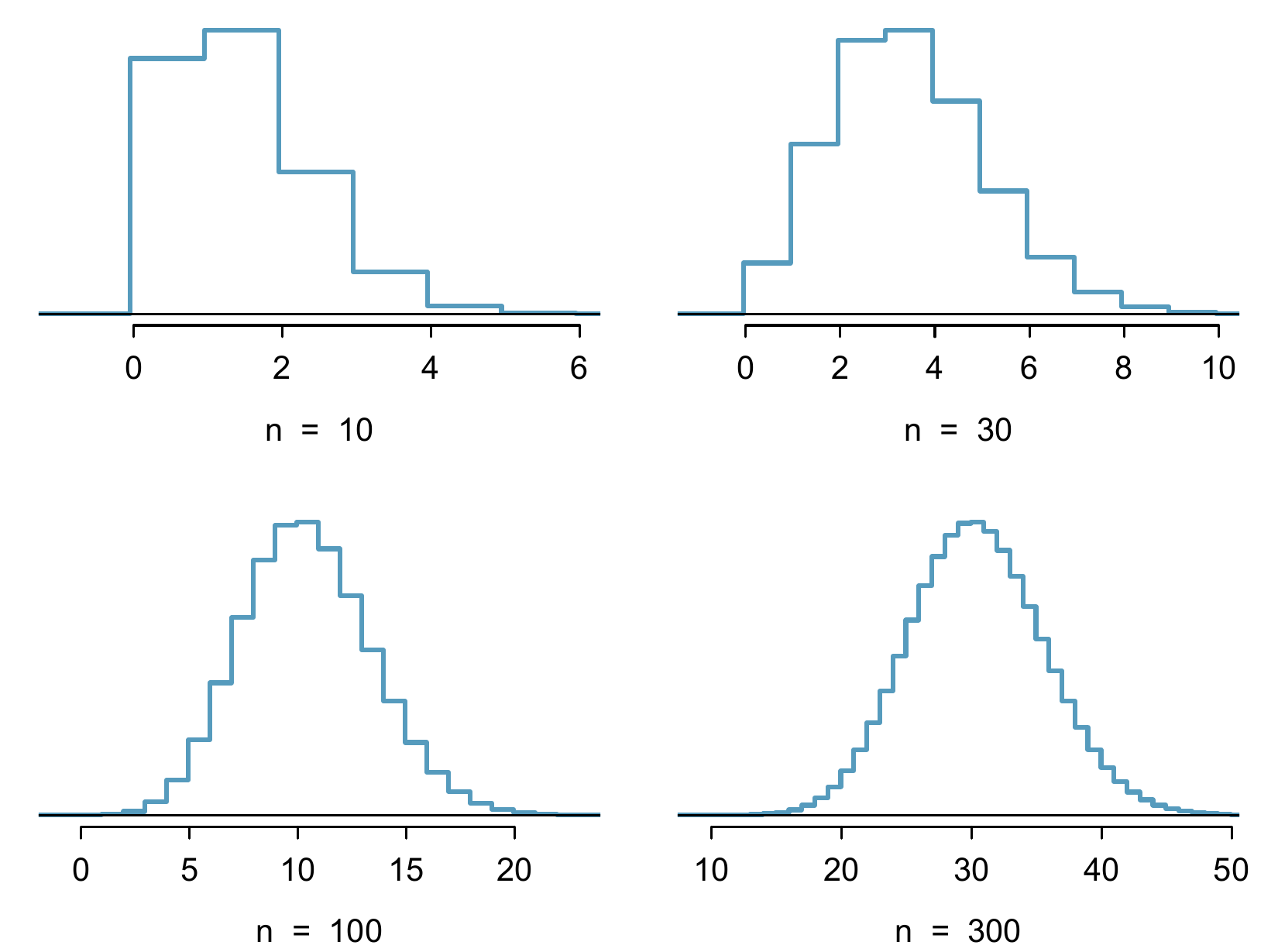
Figure 8.13: Hollow histograms of samples from the binomial model when \(p=0.10\). The sample sizes for the four plots are \(n=10\), 30, 100, and 300, respectively.
The normal approximation may be used when computing the range of many possible successes. For instance, we may apply the normal distribution to the setting of Example 8.15.
Example 8.16 How can we use the normal approximation to estimate the probability of observing 39 or fewer smokers in a sample of 400, if the true proportion of smokers is \(p=0.145\)?
Showing that the binomial model is reasonable was a suggested exercise in Example 8.15. We also verify that both \(np\) and \(n(1-p)\) are at least 10: \[ \begin{aligned} np&=400\times 0.145=58\\ n(1-p)&=400\times 0.855=342 \end{aligned} \] With these conditions checked, we may use the normal approximation in place of the binomial distribution using the mean and standard deviation from the binomial model: \[ \begin{aligned} \mu &= np = 58\\ \sigma &= \sqrt{np(1-p)} = 7.04 \end{aligned} \] We want to find the probability of observing fewer than 39 smokers using this model.It is also introduced as the Gaussian distribution after Carl Friedrich Gauss, the first person to formalize its mathematical expression.↩︎
(a) \(N(\mu=5,\sigma=3)\). (b) \(N(\mu=-100, \sigma=10)\). (c) \(N(\mu=2, \sigma=9)\).↩︎
\(Z_{Tom} = \frac{x_{Tom} - \mu_{ACT}}{\sigma_{ACT}} = \frac{24 - 21}{5} = 0.6\)↩︎
(a) Its \(Z\)-score is given by \(Z = \frac{x-\mu}{\sigma} = \frac{5.19 - 3}{2} = 2.19/2 = 1.095\). (b) The observation \(x\) is 1.095 standard deviations above the mean. We know it must be above the mean since \(Z\) is positive.↩︎
For \(x_1=95.4\) mm: \(Z_1 = \frac{x_1 - \mu}{\sigma} = \frac{95.4 - 92.6}{3.6} = 0.78\). For \(x_2=85.8\) mm: \(Z_2 = \frac{85.8 - 92.6}{3.6} = -1.89\).↩︎
Because the absolute value of \(Z\)-score for the second observation is larger than that of the first, the second observation has a more unusual head length.↩︎
If 84% had lower scores than Ann, the proportion of people who had better scores must be 16%. (Generally ties are ignored when the normal model, or any other continuous distribution, is used.)↩︎
We found the probability in Example 8.2: 0.6664. A picture for this exercise is represented by the shaded area below “0.6664” in Example 8.2.↩︎
If Edward did better than 37% of SAT takers, then about 63% must have done better than him.
 ↩︎
↩︎Numerical answers: (a) 0.9772. (b) 0.0228.↩︎
This sample was taken from the USDA Food Commodity Intake Database.↩︎
First put the heights into inches: 67 and 76 inches. Figures are shown below. (a) \(Z_{Mike} = \frac{67 - 70}{3.3} = -0.91\ \to\ 0.1814\). (b) \(Z_{Jim} = \frac{76 - 70}{3.3} = 1.82\ \to\ 0.9656\).
 ↩︎
↩︎Remember: draw a picture first, then find the \(Z\)-score. (We leave the pictures to you.) The \(Z\)-score can be found by using the percentiles and the normal probability table. (a) We look for 0.95 in the probability portion (middle part) of the normal probability table, which leads us to row 1.6 and (about) column 0.05, i.e. \(Z_{95}=1.65\). Knowing \(Z_{95}=1.65\), \(\mu = 1500\), and \(\sigma = 300\), we setup the \(Z\)-score formula: \(1.65 = \frac{x_{95} - 1500}{300}\). We solve for \(x_{95}\): \(x_{95} = 1995\). (b) Similarly, we find \(Z_{97.5} = 1.96\), again setup the \(Z\)-score formula for the heights, and calculate \(x_{97.5} = 76.5\).↩︎
Numerical answers: (a) 0.1131. (b) 0.3821.↩︎
This is an abbreviated solution. (Be sure to draw a figure!) First find the percent who get below 1500 and the percent that get above 2000: \(Z_{1500} = 0.00 \to 0.5000\) (area below), \(Z_{2000} = 1.67 \to 0.0475\) (area above). Final answer: \(1.0000-0.5000 - 0.0475 = 0.4525\).↩︎
5’5’’ is 65 inches. 5’7’’ is 67 inches. Numerical solution: \(1.000 - 0.0649 - 0.8183 = 0.1168\), i.e. 11.68%.↩︎
First draw the pictures. To find the area between \(Z=-1\) and \(Z=1\), use the normal probability table to determine the areas below \(Z=-1\) and above \(Z=1\). Next verify the area between \(Z=-1\) and \(Z=1\) is about 0.68. Repeat this for \(Z=-2\) to \(Z=2\) and also for \(Z=-3\) to \(Z=3\).↩︎
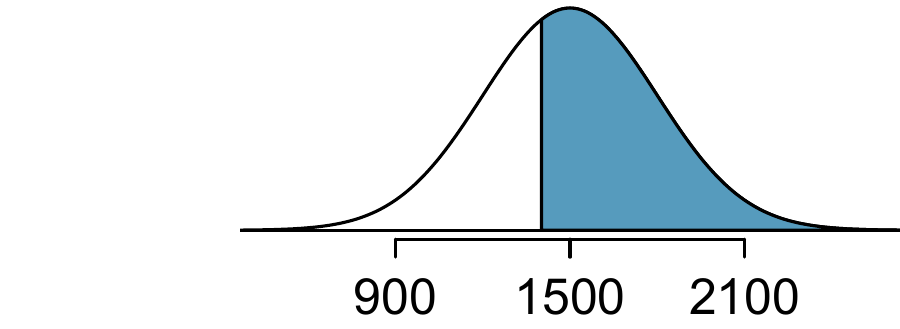
(a) 900 and 2100 represent two standard deviations above and below the mean, which means about 95% of test takers will score between 900 and 2100. (b) Since the normal model is symmetric, then half of the test takers from part (a) (\(\frac{95\%}{2} = 47.5\%\) of all test takers) will score 900 to 1500 while 47.5% score between 1500 and 2100.↩︎
Also commonly called a quantile-quantile plot or Q-Q plot↩︎
These data were collected from www.nba.com.↩︎
Answers may vary a little. The top-left plot shows some deviations in the smallest values in the data set; specifically, the left tail of the data set has some outliers we should be wary of. The top-right and bottom-left plots do not show any obvious or extreme deviations from the lines for their respective sample sizes, so a normal model would be reasonable for these data sets. The bottom-right plot has a consistent curvature that suggests it is not from the normal distribution. If we examine just the vertical coordinates of these observations, we see that there is a lot of data between -20 and 0, and then about five observations scattered between 0 and 70. This describes a distribution that has a strong right skew.↩︎
Examine where the points fall along the vertical axis. In the first plot, most points are near the low end with fewer observations scattered along the high end; this describes a distribution that is skewed to the high end. The second plot shows the opposite features, and this distribution is skewed to the low end.↩︎
Find further information on Milgram’s experiment at www.cnr.berkeley.edu/ucce50/ag-labor/7article/article35.htm.↩︎
If \({p}\) is the true probability of a success, then the mean of a Bernoulli random variable \(X\) is given by \[ \begin{aligned} \mu = E[X] &= P(X=0)\times0 + P(X=1)\times1 \\ &= (1-p)\times0 + p\times 1 = 0+p = p \end{aligned} \] Similarly, the variance of \(X\) can be computed: \[ \begin{aligned} \sigma^2 &= {P(X=0)(0-p)^2 + P(X=1)(1-p)^2} \\ &= {(1-p)p^2 + p(1-p)^2} = {p(1-p)} \end{aligned} \] The standard deviation is \(\sigma=\sqrt{p(1-p)}\).↩︎
This is hypothetical since, in reality, this sort of study probably would not be permitted any longer under current ethical standards.↩︎
We would expect to see about \(1/0.35 = 2.86\) individuals to find the first success.↩︎
First find the probability of the complement: \(P(\)no success in first 4~trials\() = 0.65^4 = 0.18\). Next, compute one minus this probability: \(1-P(\)no success in 4 trials\() = 1-0.18 = 0.82\).↩︎
No. The geometric distribution is always right skewed and can never be well-approximated by the normal model.↩︎
\(P(A=\texttt{shock},\text{ }B=\texttt{refuse},\text{ }C=\texttt{shock},\text{ }D=\texttt{shock}) = (0.65)(0.35)(0.65)(0.65) = (0.35)^1(0.65)^3\).↩︎
Other notation for \(n\) choose \(k\) includes \(_nC_k\), \(C_n^k\), and \(C(n,k)\).↩︎
We are asked to determine the expected number (the mean) and the standard deviation, both of which can be directly computed from the formulas in Equation (8.5): \(\mu=np = 40\times 0.35 = 14\) and \(\sigma = \sqrt{np(1-p)} = \sqrt{40\times 0.35\times 0.65} = 3.02\). Because very roughly 95% of observations fall within 2 standard deviations of the mean, we would probably observe at least 8 but less than 20 individuals in our sample who would refuse to administer the shock.↩︎
One possible answer: if the friends know each other, then the independence assumption is probably not satisfied. For example, acquaintances may have similar smoking habits.↩︎
To check if the binomial model is appropriate, we must verify the conditions. (i) Since we are supposing we can treat the friends as a random sample, they are independent. (ii) We have a fixed number of trials (\(n=4\)). (iii) Each outcome is a success or failure. (iv) The probability of a success is the same for each trials since the individuals are like a random sample (\(p=0.3\) if we say a “success” is someone getting a lung condition, a morbid choice). Compute parts (a) and (b) from the binomial formula in Equation (8.4): \(P(0) = {4 \choose 0} (0.3)^0 (0.7)^4 = 1\times1\times0.7^4 = 0.2401\), \(P(1) = {4 \choose 1} (0.3)^1(0.7)^{3} = 0.4116\). Note: \(0!=1\). Part (c) can be computed as the sum of parts (a) and (b): \(P(0) + P(1) = 0.2401 + 0.4116 = 0.6517\). That is, there is about a 65% chance that no more than one of your four smoking friends will develop a severe lung condition.↩︎
The complement (no more than one will develop a severe lung condition) as computed in Guided Practice 8.25 as 0.6517, so we compute one minus this value: 0.3483.↩︎
(a) \(\mu=0.3\times7 = 2.1\). (b) \(P(0, 1,\text{ or }2\text{ develop severe lung condition}) = P(k=0) + P(k=1)+P(k=2) = 0.6471\).↩︎
Frame these expressions into words. How many different ways are there to arrange 0 successes and \(n\) failures in \(n\) trials? (1 way.) How many different ways are there to arrange \(n\) successes and 0 failures in \(n\) trials? (1 way.)↩︎
One success and \(n-1\) failures: there are exactly \(n\) unique places we can put the success, so there are \(n\) ways to arrange one success and \(n-1\) failures. A similar argument is used for the second question. Mathematically, we show these results by verifying the following two equations:\({n \choose 1} = n, \qquad {n \choose n-1} = n\)↩︎
http://www.abs.gov.au/AUSSTATS/abs@.nsf/DetailsPage/4364.0.55.0012014-15?OpenDocument ↩︎
The distribution is transformed from a blocky and skewed distribution into one that rather resembles the normal distribution in the last hollow histogram.↩︎
Compute the \(Z\)-score first: \(Z=\frac{39 - 58}{7.04} = -2.70\). The corresponding left tail area is 0.0035.↩︎